Prompt Engineering for Operations: Patterns That Actually Work

Henry Froz
Head of AI
11 min read

After analyzing 10,000+ automated operational workflows, these are the prompting structures that produce consistent, high-quality results.
Most operational AI deployments underperform not because the underlying model is weak, but because the prompts feeding it are vague, inconsistent, or missing critical context. Prompt engineering for production operations is a discipline, and it separates teams getting 10× value from teams getting mediocre output from exactly the same model.
This post is based on analysis of over 10,000 operational AI workflows running on the Nexus platform ticket routing, customer health summaries, escalation reports, automated responses, and more.
We identified which patterns consistently produce high-quality, reliable output, and which anti-patterns silently destroy it. It pairs directly with the architectural guide in our post on AI agents in business operations.
Why prompt quality outweighs model quality
Teams spend enormous energy evaluating which AI model to use and relatively little time on prompt design. This is backwards. A carefully crafted prompt on a mid-tier model consistently outperforms a lazy prompt on the best available model.
The reason: large language models are pattern-completion engines. They amplify whatever signal or noise you give them. If you start with ambiguity, you get ambiguous completions.
If you start with precision, you get precise completions. The model's job is amplification. Your job is signal quality.
For operational use cases, this has a specific implication: your prompts need to encode the expertise of your best people, not your average ones.
The prompt should represent how your most senior operations manager thinks about a ticket, a customer health signal, or an escalation decision.

The four-component prompt structure Role, Task, Format, Constraint applied to a churn-assessment workflow
The five patterns that consistently work
Pattern 1 - Role + Task + Format + Constraint
The most reliable structure for operational prompts combines four elements: who the AI is (role), what it must do (task), how the output should look (format), and what it must never do (constraint). This structure eliminates 80% of the ambiguity that causes inconsistent output. Every production prompt in a Nexus workflow uses this skeleton.
Pattern 2 - Few-shot examples calibrate judgment
For classification tasks, showing the model 3–5 labelled examples before the real input dramatically improves consistency. The examples don't just teach the model a concept they teach your specific definitions. For ticket routing, show three tickets with their correct urgency scores before the live ticket. We see 35–40% quality improvement on average from adding three well-chosen examples.
## Example 1 Ticket: "My payment failed and I can't access my account." Classification: Billing | P1 ## Example 2 Ticket: "Can you add dark mode to the dashboard?"Classification: Feature Request | P3 ## Now classify this: Ticket: {{incoming_ticket}}
Pattern 3 - Chain-of-thought for complex decisions
For multi-variable decisions customer health scoring, escalation routing, contract renewal risk instruct the model to "think step by step before reaching a conclusion." This produces more accurate outputs and, crucially, generates reasoning that humans can audit and correct.
In operational AI, auditable reasoning is not a nice-to-have. It is a compliance and trust requirement.
Pattern 4 - Explicit uncertainty handling
Tell your model what to do when it's unsure. Prompts that don't handle uncertainty produce confident wrong answers the worst outcome in an operational context. The pattern: "If you cannot classify with 80%+ confidence, output UNCERTAIN and list the two most likely classifications with your reasoning." This converts silent failures into explicit escalations that humans can resolve.
Pattern 5 - Deliberate context scoping
Operational prompts often include long context: ticket history, customer notes, past interactions. More context is not always better irrelevant context adds noise and degrades output quality.
The rule that works: include the last 3 interactions verbatim, summarize anything older into 2–3 sentences. Test your prompts both with and without historical context; sometimes the shorter prompt wins.
The five anti-patterns that destroy quality
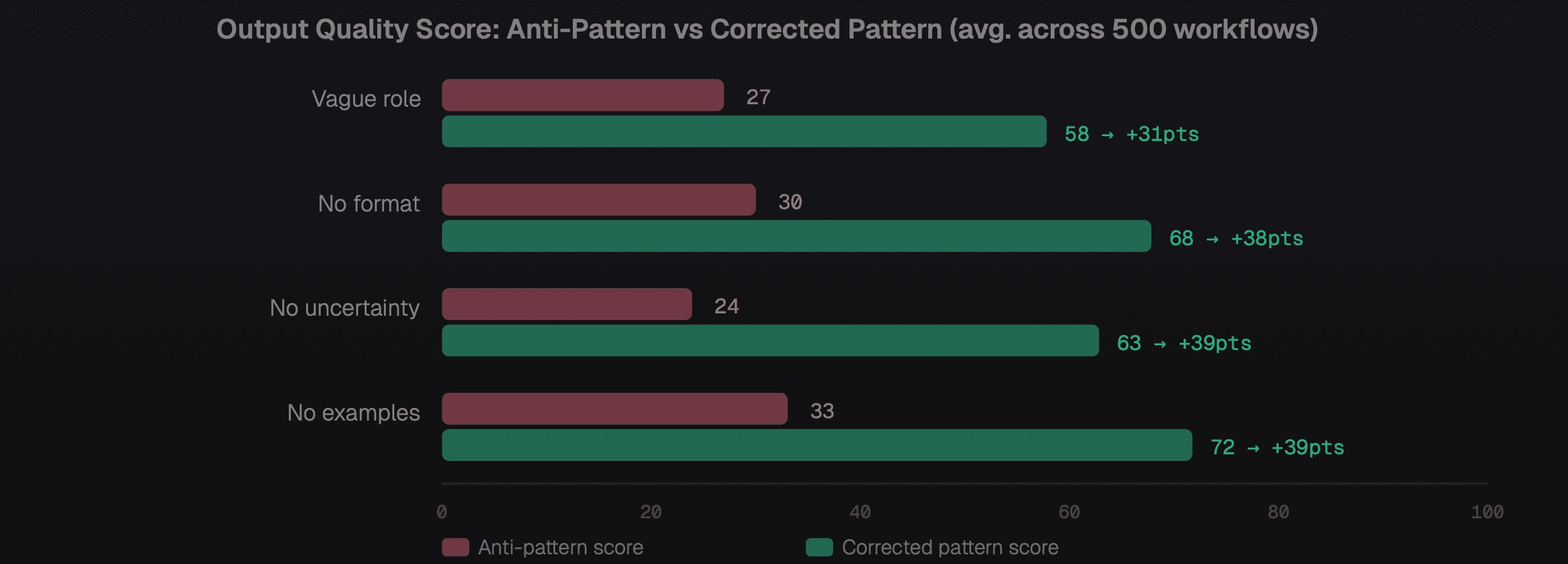
Quality score comparison anti-pattern prompts vs corrected equivalents across 500 operational workflows
Anti-pattern 1 - "You are a helpful assistant"
This tells the model nothing about level of judgment, domain expertise, or decision-making authority. A role must be specific: "You are a senior enterprise account manager with 8 years of B2B SaaS experience, specialising in healthcare compliance clients." The domain and experience level calibrate the model's vocabulary, risk tolerance, and tone.
Anti-pattern 2 - No output format specification
Prompts without explicit format requirements produce outputs that are hard to parse programmatically. If your workflow needs JSON, say so and provide the exact schema with field names and types. If you need bullet points, cap the count. Unconstrained outputs are unpredictable at scale and break downstream automation.
Anti-pattern 3 - Contradictory instructions
A prompt that says "be concise" in one place and "include all relevant context" in another creates model confusion. The model will follow one instruction inconsistently and violate the other. Audit every production prompt for contradictions especially prompts updated incrementally over time.
Anti-pattern 4 - No evaluation loop
Most teams ship a prompt, observe qualitative results, and never formally measure accuracy. Build a weekly eval loop: sample 50–100 outputs, score them against ground truth or human judgment, track accuracy over time. Without this, you cannot tell if your "improvements" actually improved anything. This connects to the performance measurement framework in our AI agents guide.
Anti-pattern 5 - Treating prompts as one-time setup
Prompts need to evolve as your product, customers, and edge cases change. Create a prompt registry with version control. Every change to a production prompt should be tested against a held-out evaluation set before deployment.
Treat prompts like code because they are code. Teams that version-control their prompts have 3× lower error rates on production workflows than teams that manage them informally.
Building your prompt library
The highest-leverage investment for most ops teams is a centralized, version-controlled prompt library. Every workflow prompt should have: a version number, the eval criteria it must pass before promotion to production, a test set of at least 20 examples, and a record of measured accuracy over time.
Even a simple Notion table with version history and accuracy tracking beats managing prompts informally in a codebase. Nexus's automation module includes a built-in prompt registry with version history and eval tracking for teams who want it out of the box.
For the broader AI architecture these prompts plug into, see our guide on AI agents in business operations. For the automation workflows that consume these prompts at scale, read our post on what to automate first. And for teams building AI-informed product strategy, our guide to building an AI-first product roadmap covers the product-level decisions that complement great operational prompts.
The best operational AI isn't built on the best model. It's built on the best-designed prompts, the most rigorous evaluation process, and the most intentional feedback loops. The model is the engine. The prompt is the steering wheel.
Prompt engineering for operations is a craft that compounds. Every improvement to a production prompt improves every workflow that uses it.
Teams that build the discipline early versioning, evaluation, structured patterns create a durable advantage that widens as they scale.


